Published
Author Roderic Page
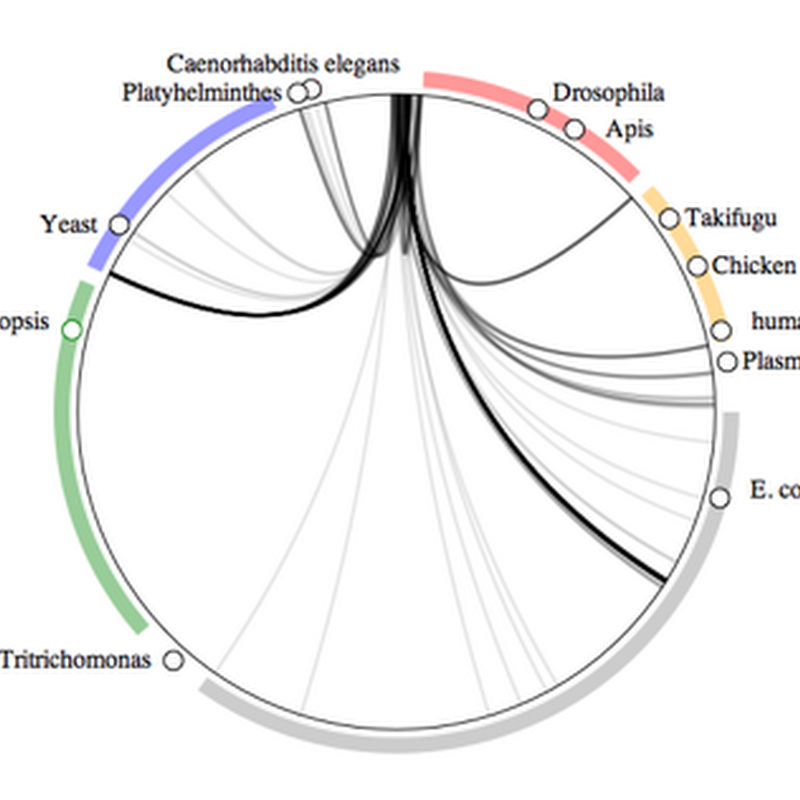
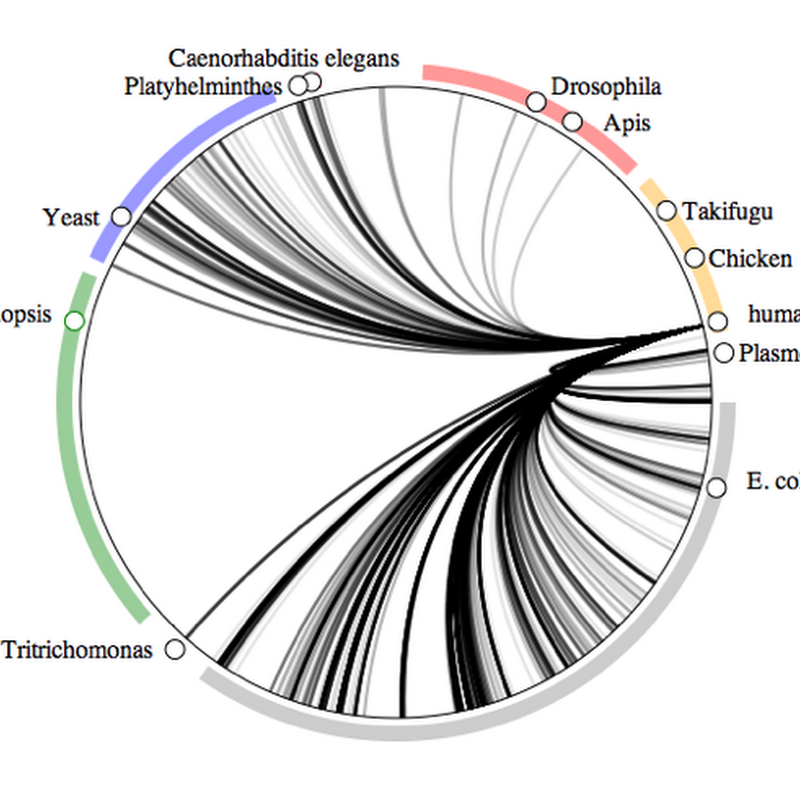
My article describing BioStor — "Extracting scientific articles from a large digital archive: BioStor and the Biodiversity Heritage Library" — has finally seen the light of day in BMC Bioinformatics (doi:10.1186/1471-2105-12-187, the DOI is not working at the moment, give it a little while to go live, meantime you can access the article here). Getting this article published was more work than I expected.