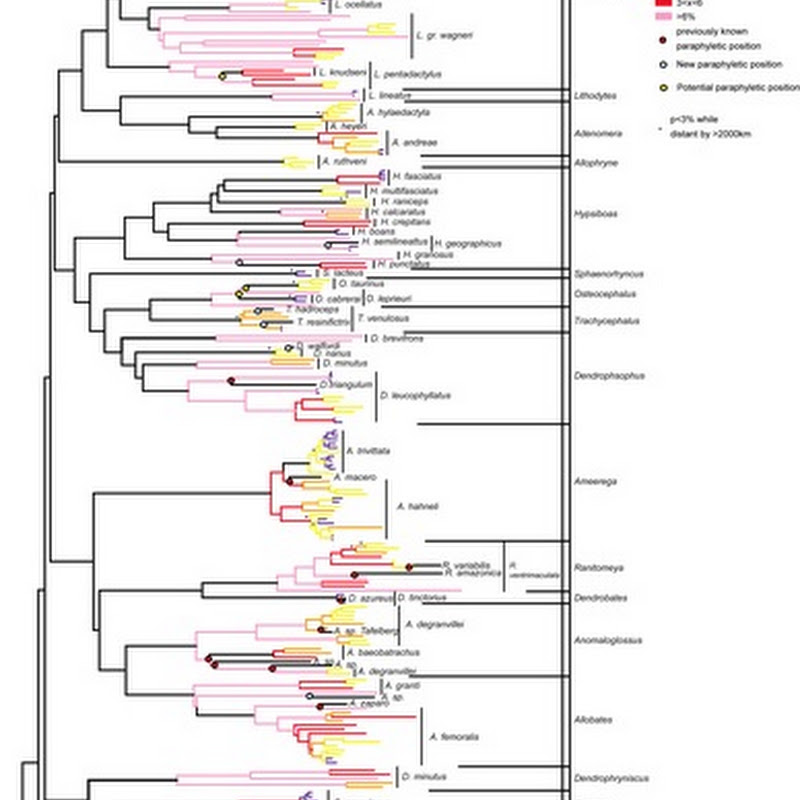
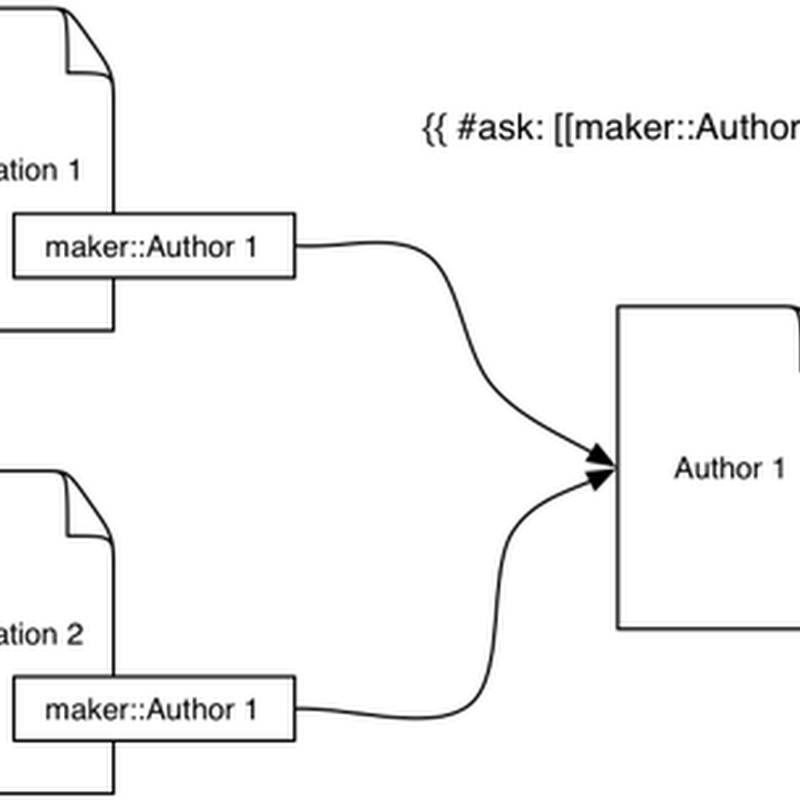
Published
Author Roderic Page
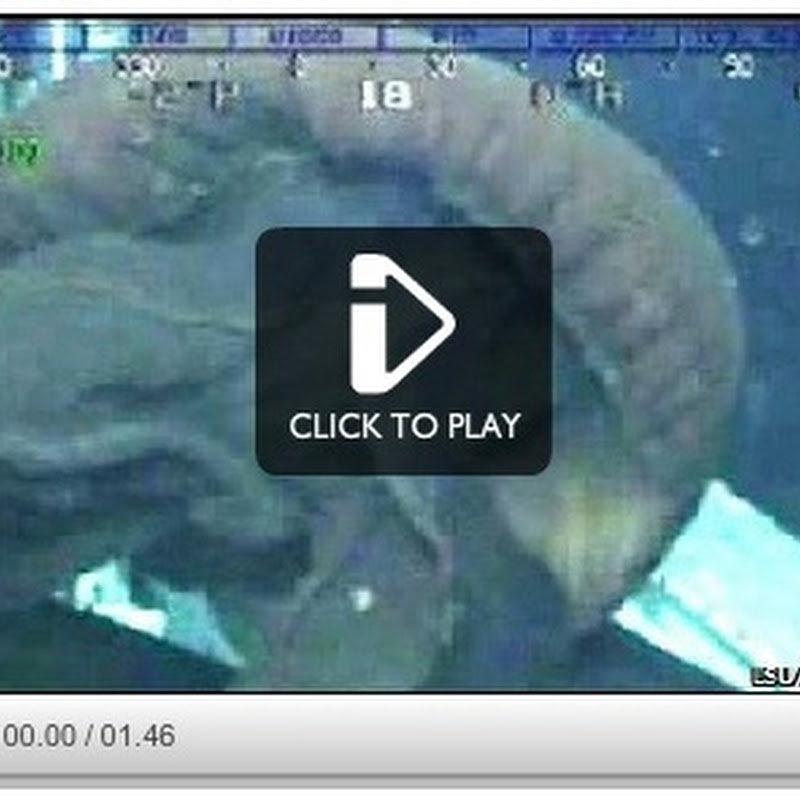
The BBC web site has an article entitled Giant deep sea jellyfish filmed in Gulf of Mexico which has footage of Stygiomedusa gigantea , and mentions an associated fish, Thalassobathia pelagica . One thing that frustrates me beyond belief is how hard it is to get more information about these organisms. Put another way, the biodiversity informatics community is missing a huge opportunity here.