Published
Author Josef Fruehwald

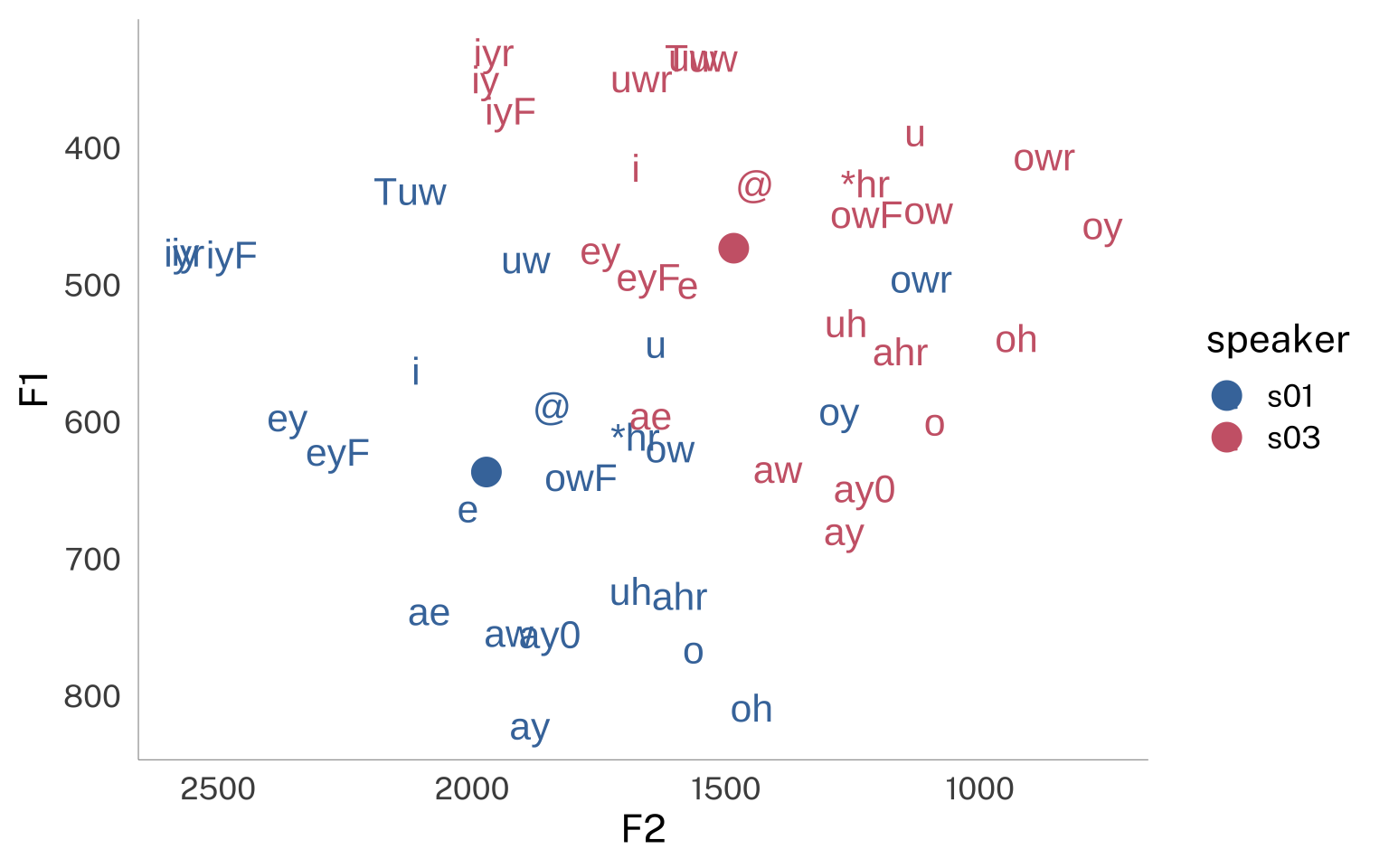
setupsource(here::here("_defaults.R")) library(tidyverse) library(brms) library(broom.mixed) library(ggdist) library(tidybayes) library(marginaleffects) library(tinytable) library(patchwork) library(faux) set.seed(2025-12-8) options(tinytable_html_mathjax = TRUE) I’ve been thinking about Causal Inference, and have run up against a kind of confusing issue when it comes to “Composite Variables”, or variables deterministically created from the