Published
Author Stephen Turner
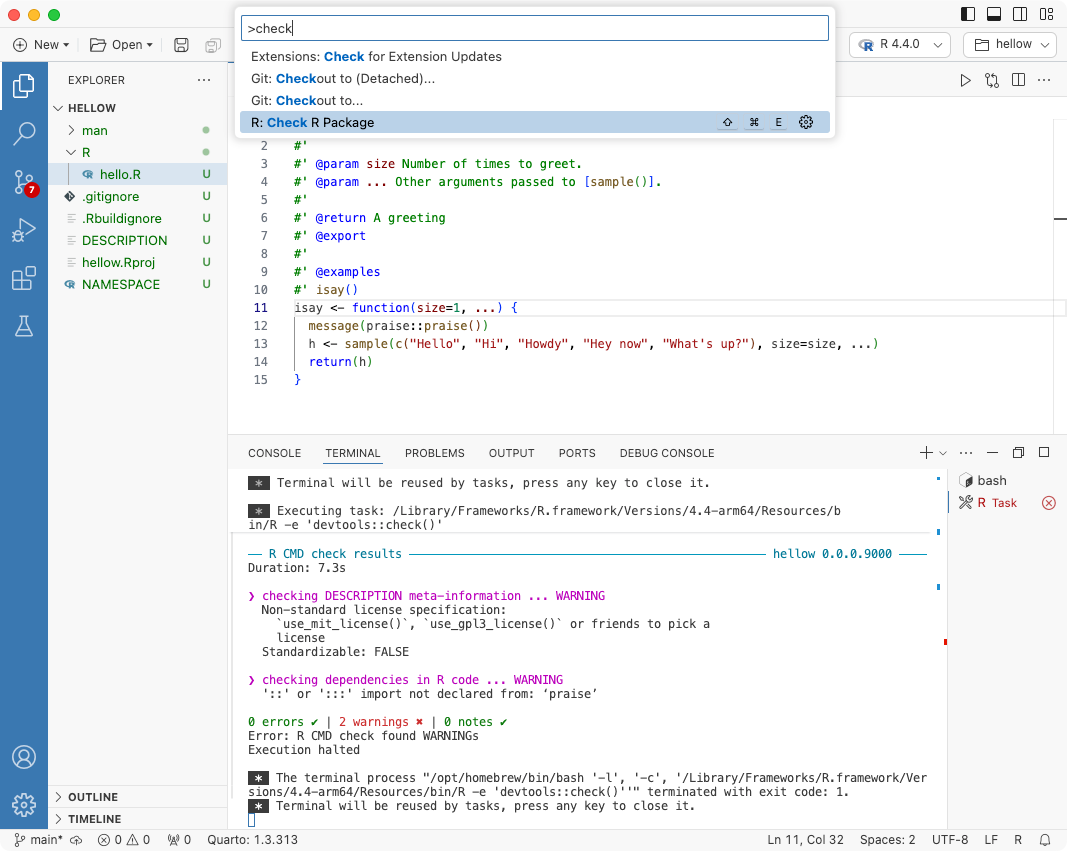
I’ve been using the llama3.1:70b model just released by Meta using Ollama running on my MacBook Pro. Ollama makes it easy to talk to a locally running LLM in the terminal (ollama run llama3.1:70b) or via a familiar GUI with the open-webui Docker container. Here I’ll demonstrate using the ollamar package on CRAN to talk to an LLM running locally on my Mac.