CommunityCrossrefMeetingsInformatikEnglisch
Veröffentlicht

This June, we presented at the Beijing International Book Fair (BIBF) and connected directly with our growing community in China.
This June, we presented at the Beijing International Book Fair (BIBF) and connected directly with our growing community in China.
Click here for the version in German As a new Community Engagement Manager at Crossref, dedicated to working with the funders community, I frequently hear requests for examples and case studies of adopting Crossref’s Grant Linking System (GLS) by ‘funders like us’. This has spurred me to start a series of
To address the growing scale and complexity of scholarly data, we’ve launched a new data science function at Crossref. In April, we were excited to welcome our first data scientists, Jason Portenoy and Alex Bédard-Vallée, to the team.
If you are reading this blog on our website, you may have noticed that alongside each post we now list a Crossref DOI link, which was not the case a few months ago (though we have retroactively added DOIs to all older posts too). You can find the persistent link

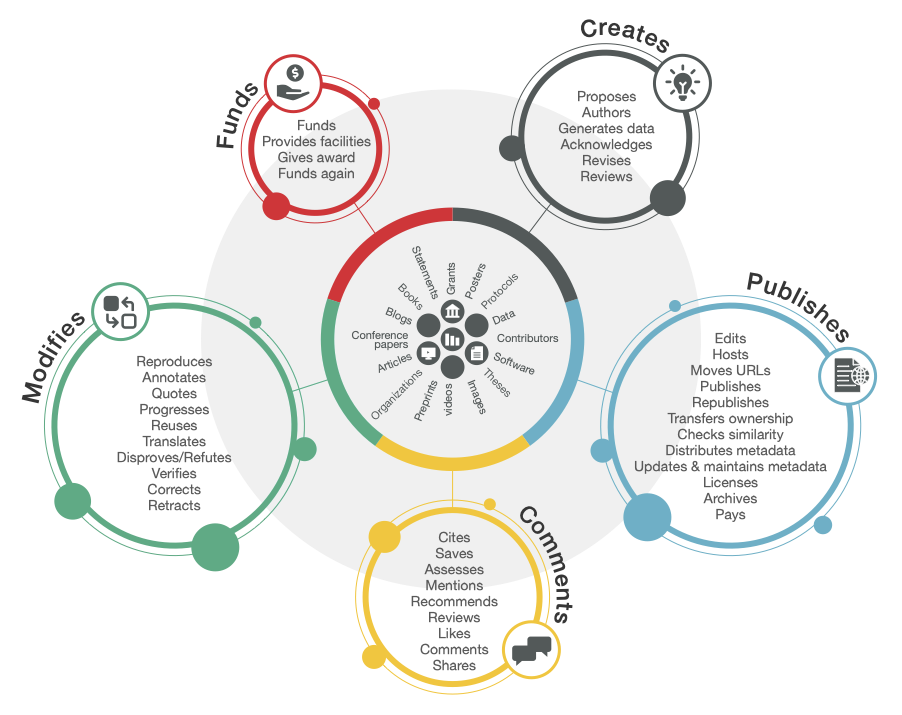
If you take a peek at our blog, you’ll notice that metadata and community are the most frequently used categories. This is not a coincidence – community is central to everything we do at Crossref. Our first-ever Metadata Sprint was a natural step in strengthening both.
This post is based on an interview with Sciety team at eLife. What is Sciety? Sciety is a community-led initiative developed by a team within eLife, that brings together expert evaluations of papers in one place. It is focused on preprints, preprint review and curation.
English version Dado que Crossref celebra su 25º aniversario este año, nos gustaría destacar algunas de las regiones activas y comprometidas en nuestra comunidad global. Durante los primeros 25 años, la composición de los miembros de Crossref ha evolucionado significativamente.
The Crossref Nominating Committee invites expressions of interest to join the Board of Directors of Crossref for the term starting in January 2026. The committee will gather responses from those interested and create the slate of candidates that our membership will vote on in an election in September.
In its March 2025 meeting, the Crossref board unanimously voted to update both the Crossref bylaws and the Crossref membership terms to: Provide more clarity and alignment between our bylaws and membership terms, where they had become out of sync over the years. Reflect previous board motions and bring both documents up-to-date with current processes for suspending and revoking membership, and reviewing those decisions.
Marking our 25th anniversary, we launch the Crossref Metadata Awards to emphasise our community’s role in stewarding and enriching the scholarly record.
We’ve been accelerating our metadata development efforts and recently released version 5.4 of our metadata schema, and are planning to release version 5.5 (including support for multiple contributor roles and the CRediT taxonomy) this summer.