WordpressPythonPHPNaturwissenschaftenEnglisch
Veröffentlicht
Autor Charles Tapley Hoyt
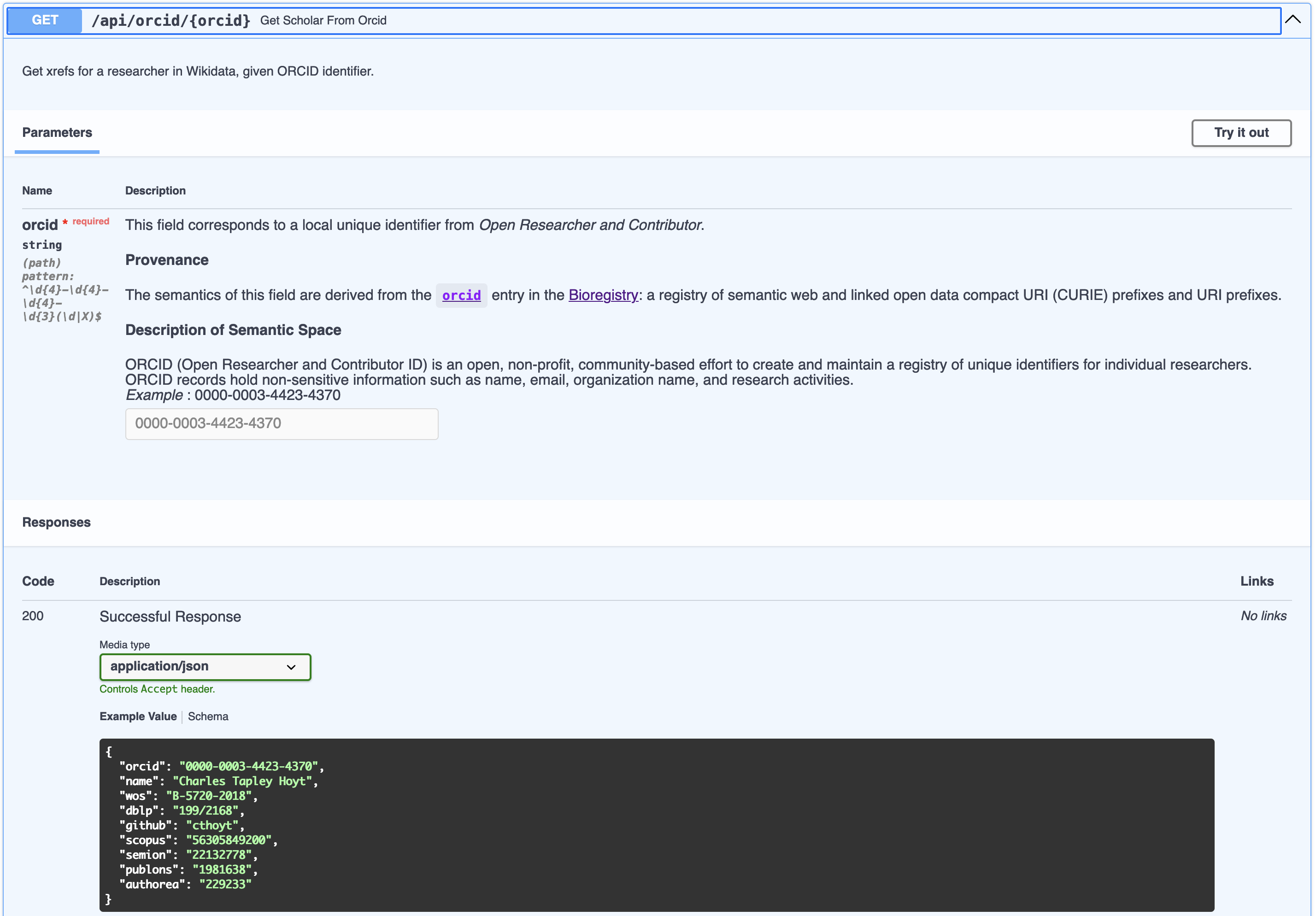
The International Society of Biocuration (ISB) partners with the journal Database to get discounts for its members when they publish there. This means the ISB’s executive committee needs to send a member list to the journal’s editor.