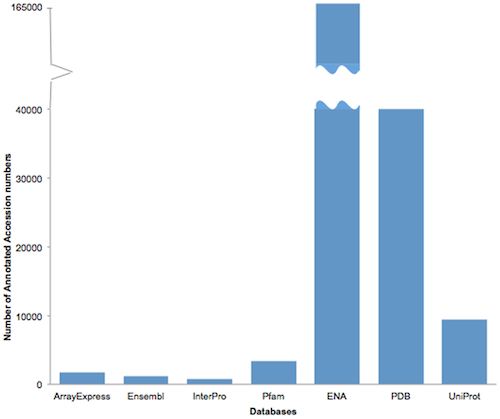
FeatureInformatikEnglisch
Veröffentlicht
Autor Martin Fenner
Ten days ago Information Standards Quarterly (ISQ) published a special issue on altmetrics. I was the guest editor for the five altmetrics articles, and in the editorial that I titled Altmetrics have come of age I argued that We no longer need to talk about whether it is possible to reliably collect altmetrics, or whether this is valuable information that can complement citations and usage statistics.