Andere SozialwissenschaftenEnglisch
Veröffentlicht
Autor Aaron Tay

null
null

It's not big secret that Machine learning and AI is an increasingly important topic to study. But I was again reminded of this again when I recently attended a talk on Microsoft Academic , entitled "What Can We Expect from Machine Cognition " The talk began simply enough, recapping some of the latest triumphs by AI in conquering games like Go and Video games like DOTA, Pacman.

As the battle for open access , or more accurately the route taken to open access rages on, I have become aware of the rise of a new type of "open" - the quest for "open infrastructure". My understanding of it is very limited, but I first seriously took note of it when I saw people tweeting about the Joint Roadmap for Open Science Tools (JROST). One of the reasons why open access is in such a mess is because we have given up the

I have been recently thinking about dataset discovery, most recently on the possible impact of Google Dataset search. One of the areas I've been investigating is the linkage between the article and the associate dataset. In particular, one of the more eye catching areas where this link appears is in Scopus, where there is a "related research data" link section.
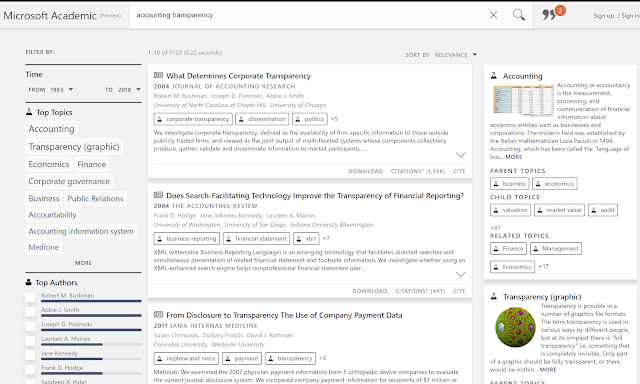
It seems like just a short time last year in May where I blogged about the new iteration of Microsoft's academic search dubbed "Microsoft Academic" which was then in beta and it eventually left beta at the end of the year. But it seems they are at it again, this time there is a Microsoft Academic Preview. On first glance this looks just like a run of mill face lift. Don't get me wrong, overall I think this is an improvement.
I’ve recently come across an idea known as inversion.

It has been a very eventful couple of weeks in the academic, publisher and library related worlds with regards to the push towards open.

Update Aug 2020 - The main thrust of this response is to point out RA21 type solutions do not handle the appropriate copy problem.
Open access is a complicated business. Everytime I think I understand it (and I've blogged a lot on it, trying too get to gripes with it - in particular this post), some new nuance appears to make me realize I don't really understand at all. In this case, my mind was blown when I learnt that there was wall of shame for posting preprints on Bioarxiv! But let's back up a bit and talk a bit about preprints first.

In the heyday of Web Scale Discovery (2009 to the early to mid 2010s), library discovery was a big issue that was front and center in our profession's sights.

4 years ago in 2014, I wrote about the coming disruption to academic libraries due to Open Access. In How academic libraries may change when Open Access becomes the norm , I wrote " The trend I am increasingly convinced that is going to have a great impact on how academic libraries will function is the rise of Open Access.