Climate ChangeClimateGeojsonGeospatialTech NotesInformatikEnglisch
Veröffentlicht
Autor Scott Chamberlain
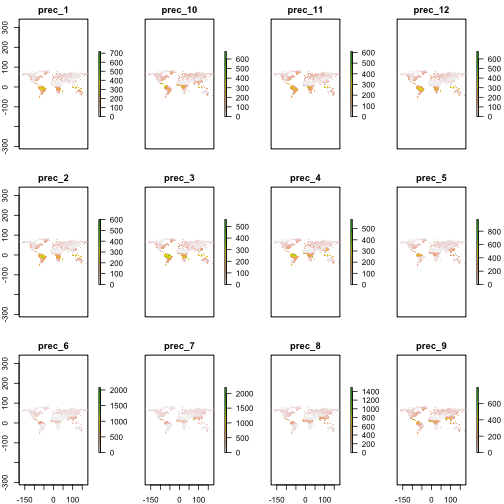
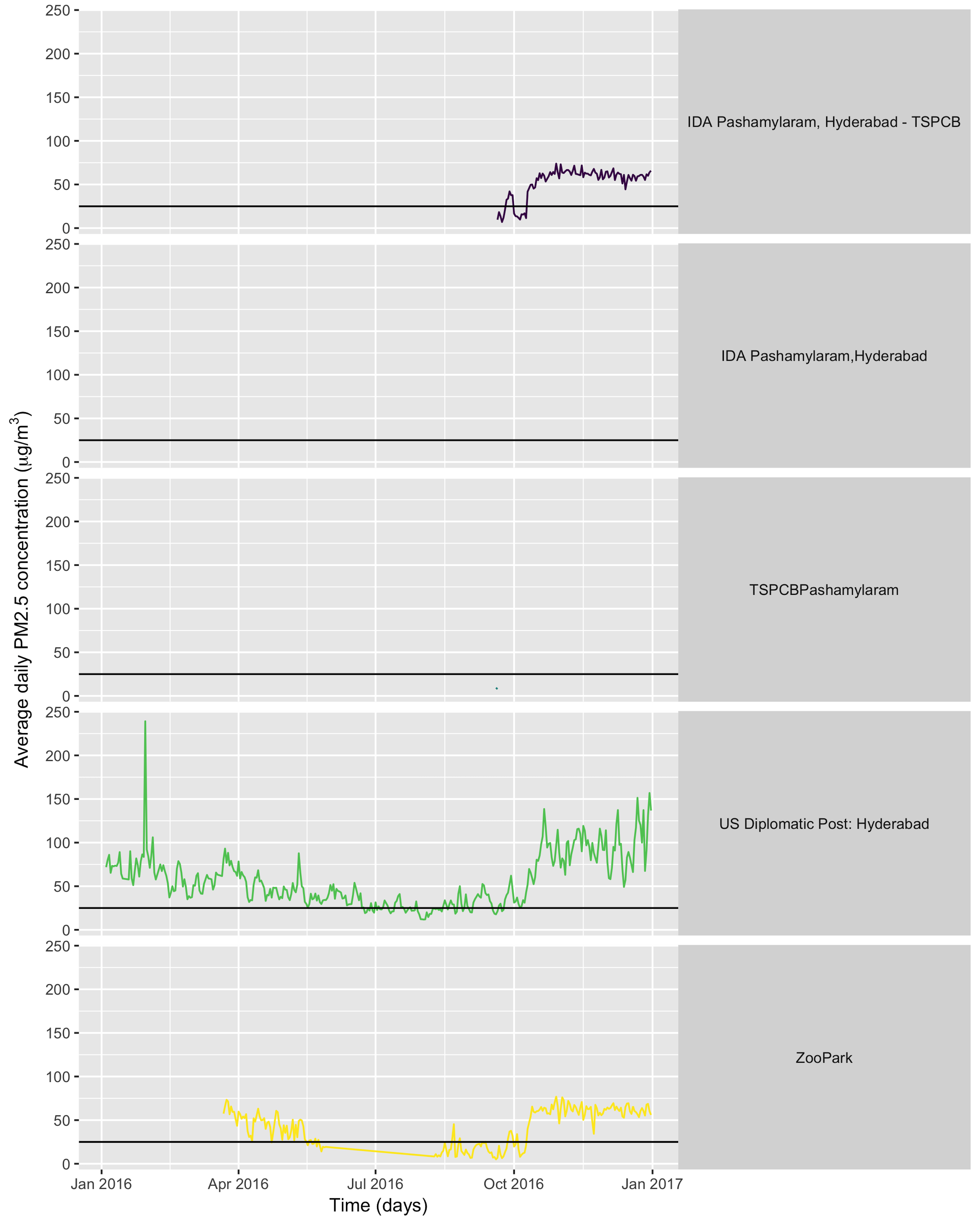
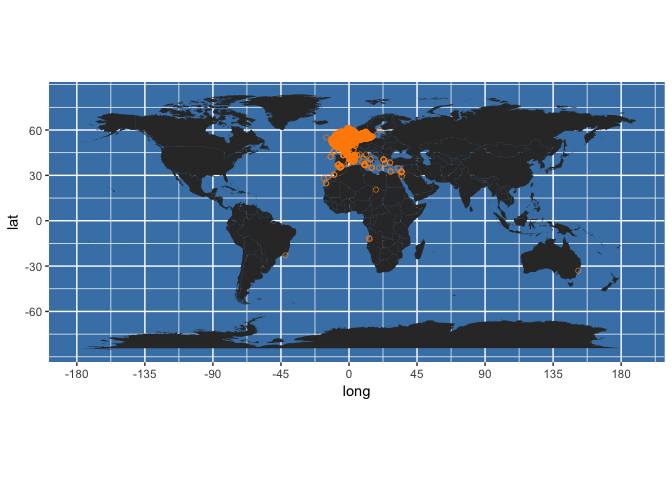
I’ve recently released the new package ccafs, which provides accessto data from Climate Change, Agriculture and Food Security(CCAFS; http://ccafs-climate.org/) General Circulation Models (GCM) data.GCM’s are a particular type of climate model, used for weather forecasting,and climate change forecasting - read more athttps://en.wikipedia.org/wiki/General_circulation_model.