Ciências NaturaisInglês
Publicados
Autor Donny Winston
This week on Machine-Centric Science, I interviewed Martynas Jusevičius, currently at AtomGraph and based in Copenhagen, Denmark.
This week on Machine-Centric Science, I interviewed Martynas Jusevičius, currently at AtomGraph and based in Copenhagen, Denmark.
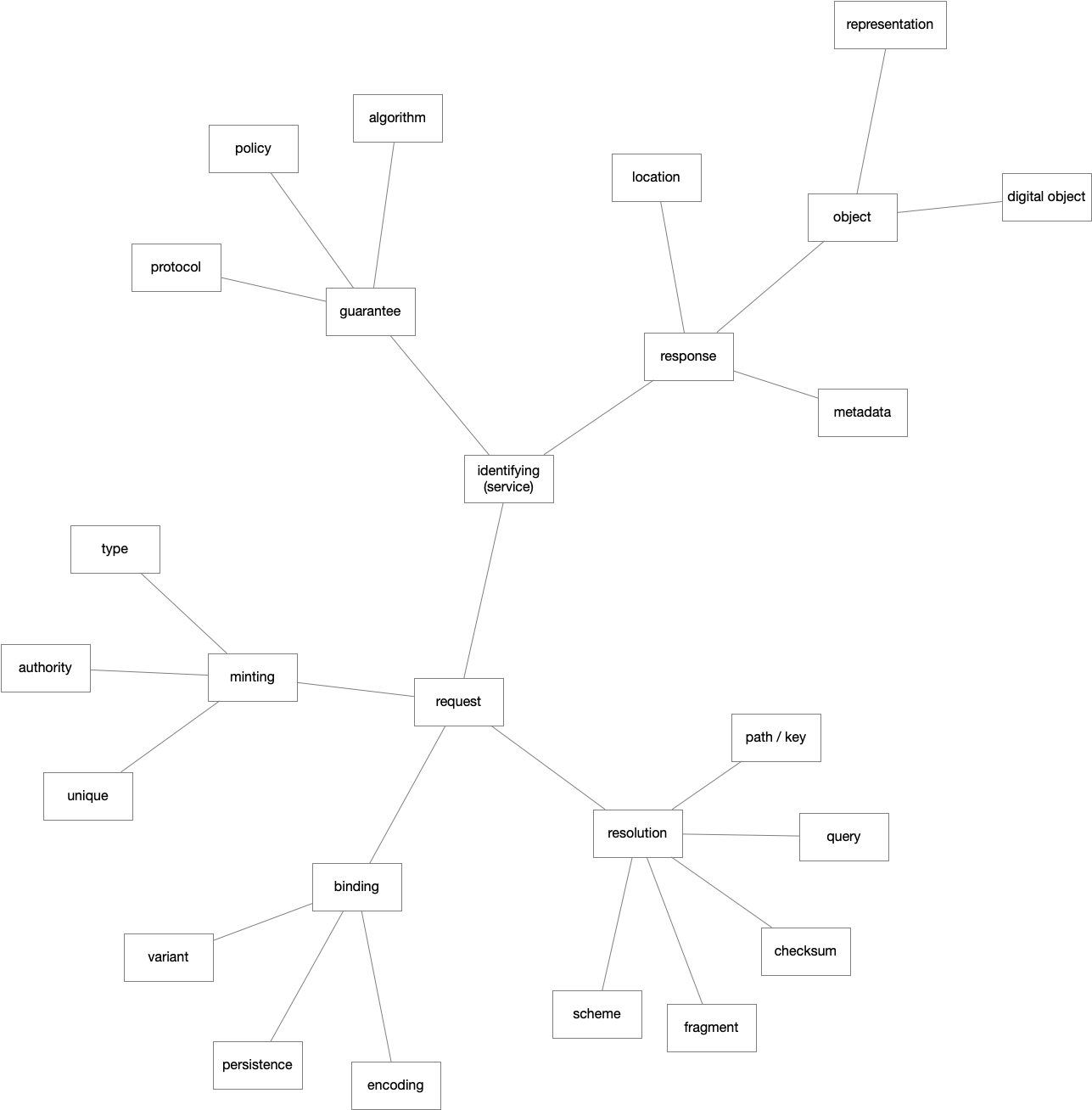
At a base level, an identifier is simple to trace – it is the sequence (modulo concurrency) of assertions of which it is a part. In fact, this can be the basis for tracing the representation of a “thing” as the flock of relationships between identifiers, i.e. metadata, that waxes and wanes in association with “the” identifier of the thing.
Good identifiers are opaque, so translation is by association – owl:sameAs, skos:exactMatch, or some other relationship. Translation doesn’t follow from reading a sign, but from retrieving a sense. If metadata is relationships between identifiers, 1 then metadata is the medium of conceptual convergence.
Where do you look for identifiers? If you’re looking for a URI, the IANA has a registry of schemes, like https, mailto, and tel. These days, to resolve an identifier, you generally use the https scheme, which has an authority component in its URI format.
How do you validate that an identifier service provides global uniqueness of minted keys, persistence of bindings, and resolution of keys to descriptive metadata? If you know that a given ID provided by a service is unique, that tells you nothing at all about the uniqueness of another ID provided by that service.
Day 1 of my five-week experiment to elaborate on FAIR-enabling services, and I already find myself fallen flat on my face.
Yesterday, I proposed that a strategy for implementing the FAIR principles for research data management can focus on ensuring five FAIR-enabling services , which in turn will prompt tactical choices of FAIR-enabling resources that may satisfactorily address each question and thereby produce a comprehensive implementation profile.
(The following is a transcript of my recent podcast episode on this topic.) There is a FAIR Implementation Profile ontology, and it talks about FAIR-enabling resources. So these are corresponding to questions.
Here are some identifier services listed as such by FIP Wizard, a free-to-signup online tool to guide a user in creating and publishing a machine-actionable FAIR Implementation Profile (FIP): Old IGSN International Generic Sample Number before integration with DataCite SDN CDI PID | SeaDataNet CDI PID SeaDataNet Common Data Persistent Identifier U.S. Department of Energy Office of Scientific and Technical Information (OSTI) Data ID Service

Repurposing data is hard sometimes. Given a current application’s data-worldview – i.e., its schema – one cannot in general pull in historical data collected for different applications because those applications had different worldviews – i.e., they used different data schemas.
Inference based on semantic retrieval is more robust than inference based on syntactic parsing. In order to be authoritative, identifiers should be assigned as early as practicable in the creation process, but minting is not binding. Identifier resolution delays binding; identifier structures induce binding. Moral: Structure identifiers late (or never) in the minting process.