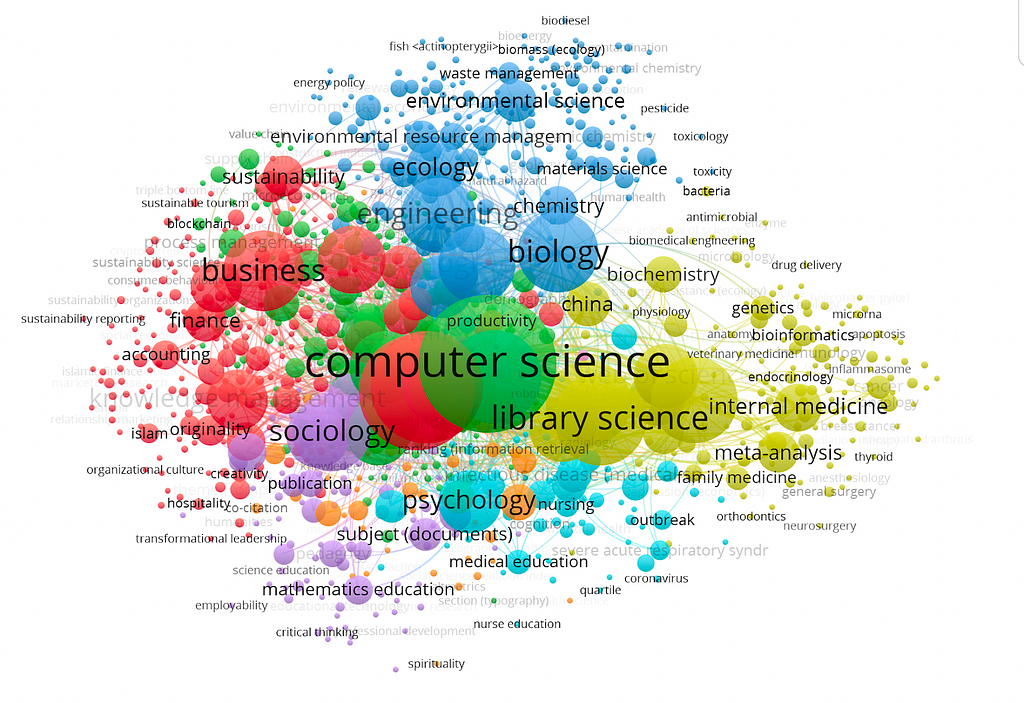
Artificial IntelligenceTocCiências da Computação e da InformaçãoInglês
Publicados
Autor Vaibhav Khobragade
Introduction Human language development is innate and evolves throughout life. Machines lack this ability to evolve without advanced artificial intelligence (AI) algorithms. Since the Turing Test was proposed in the 1950s, efforts to master machine understanding of language have led from statistical to neural language models.