FeatureBilgisayar ve Bilişim Bilimleriİngilizce
Yayınlandı
Yazar Martin Fenner

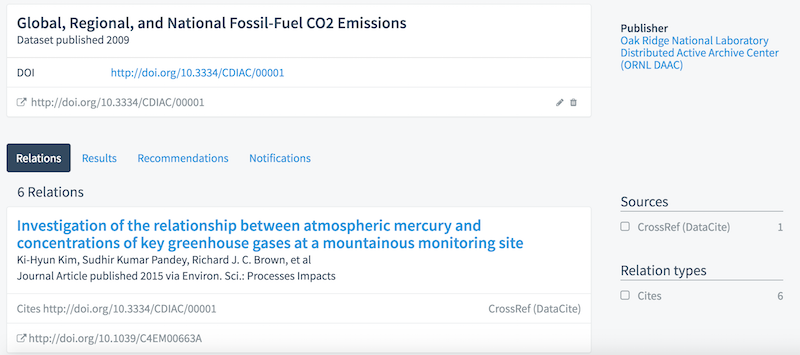
Data citation is core to DataCite's mission and DataCite is involved in several projects that try to facilitate data citation, including THOR, Data Citation Implementation Pilot (DCIP), Research Data Alliance (RDA), and COPDESS. The biggest roadblock for wider data citation adoption might be insufficient incentives for individual researchers, but another major challenge is that implementing data citation is still too complicated.