CrossrefLinkingInformática y Ciencias de la InformaciónInglés
Publicado
Autor Geoffrey Bilder
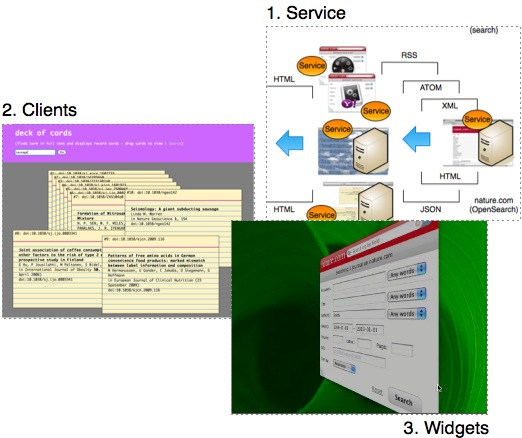
Inspired by Google’s recent promotion of QR Codes, I thought it might be fun to experiment with encoding a Crossref DOI and a bit of metadata into one of the critters.