Ciencias QuímicasInglés
Publicado
Autor Corin Wagen
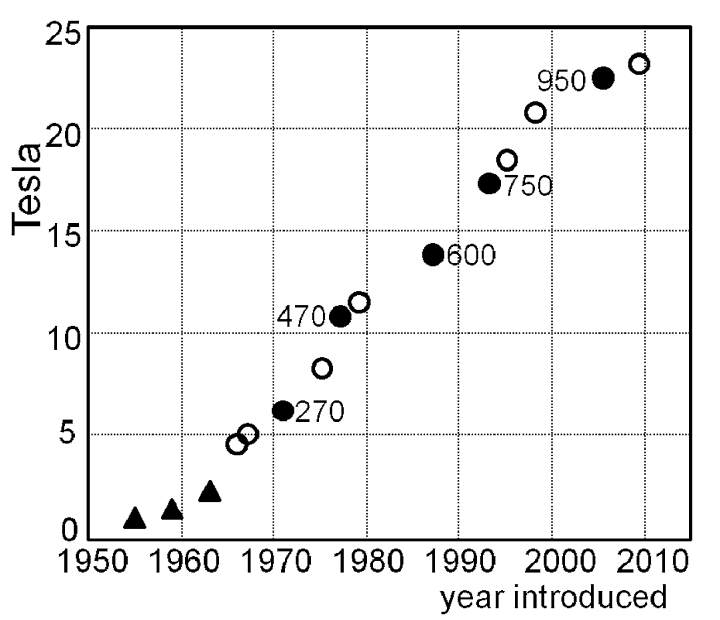
Much ink has been spilled on whether scientific progress is slowing down or not (e.g.). I don’t want to wade into that debate today—instead, I want to argue that, regardless of the rate of new discoveries, acquiring scientific data is easier now than it ever has been. There are a lot of ways one could try to defend this point;