Ciencias SocialesInglés
Publicado
Autor Josef Fruehwald
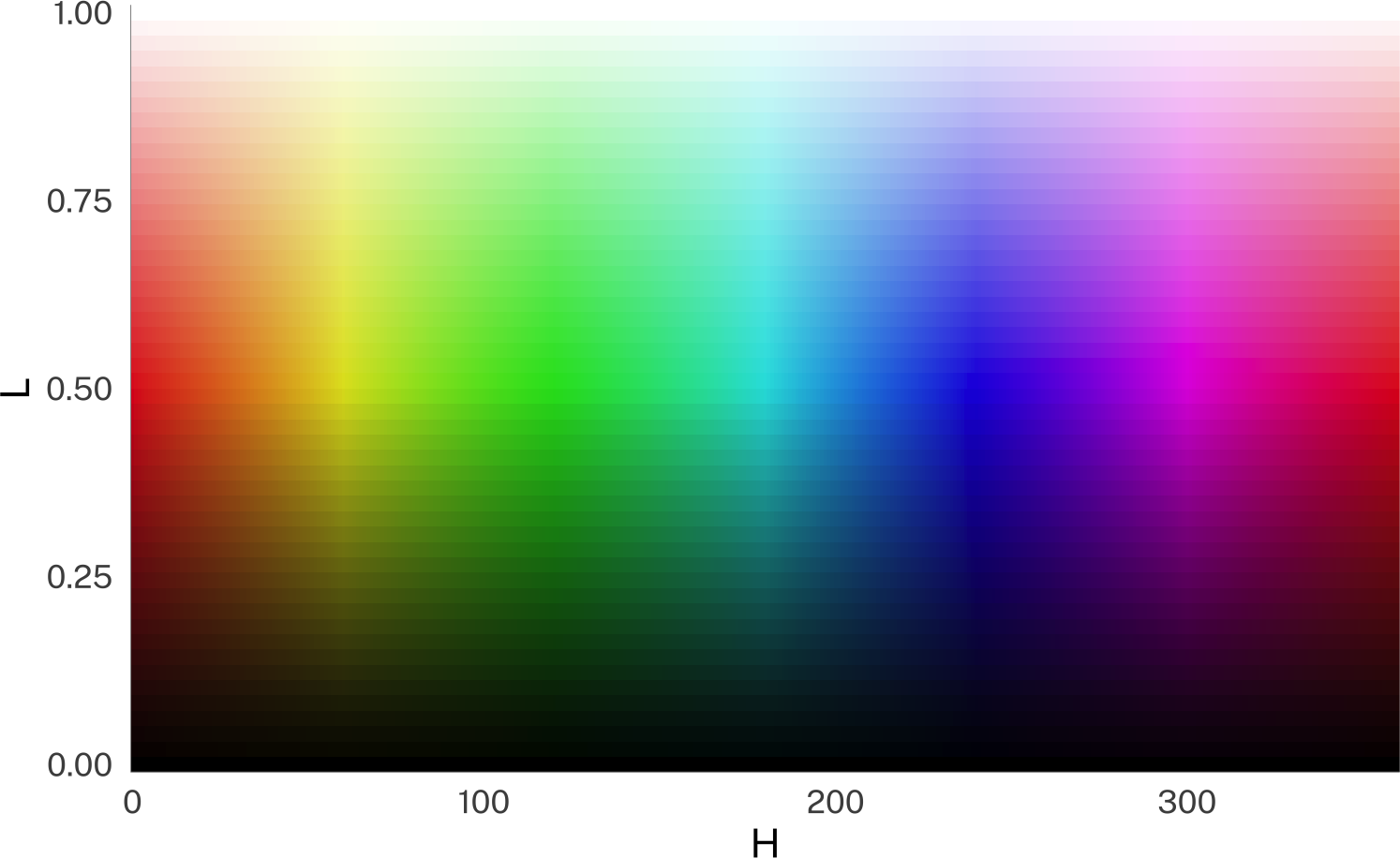
So now I can finally get to visualizing the effect of “light” and other modifiers on colors! When I eventually get to the plotly code, there’s nothing tidy going on, so I’ll be code-folding most of this stuff.