Ciencias QuímicasInglés
Publicado
Autor Richard L. Apodaca

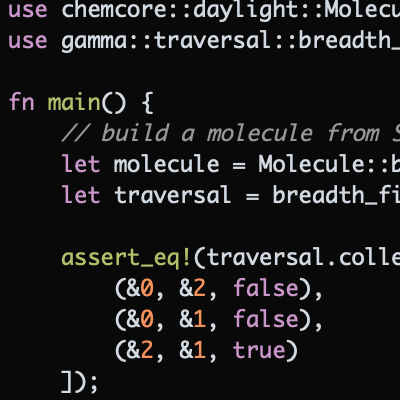
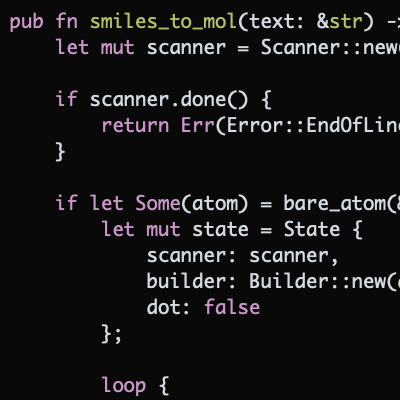
What set of features uniquely characterize a given molecule? What modes of representation should be fixed or rejected, and under what conditions? Given that machine-based molecular encodings have been in use for more than sixty years, it might seem that such questions have long since been resolved. Nevertheless, the topic casts a long shadow to this day, particularly when dataset curation or property prediction come into play.