CrossrefIdentifiersLinked DataInformatique et sciences de l'informationAnglais
Publié
Auteur Geoffrey Bilder
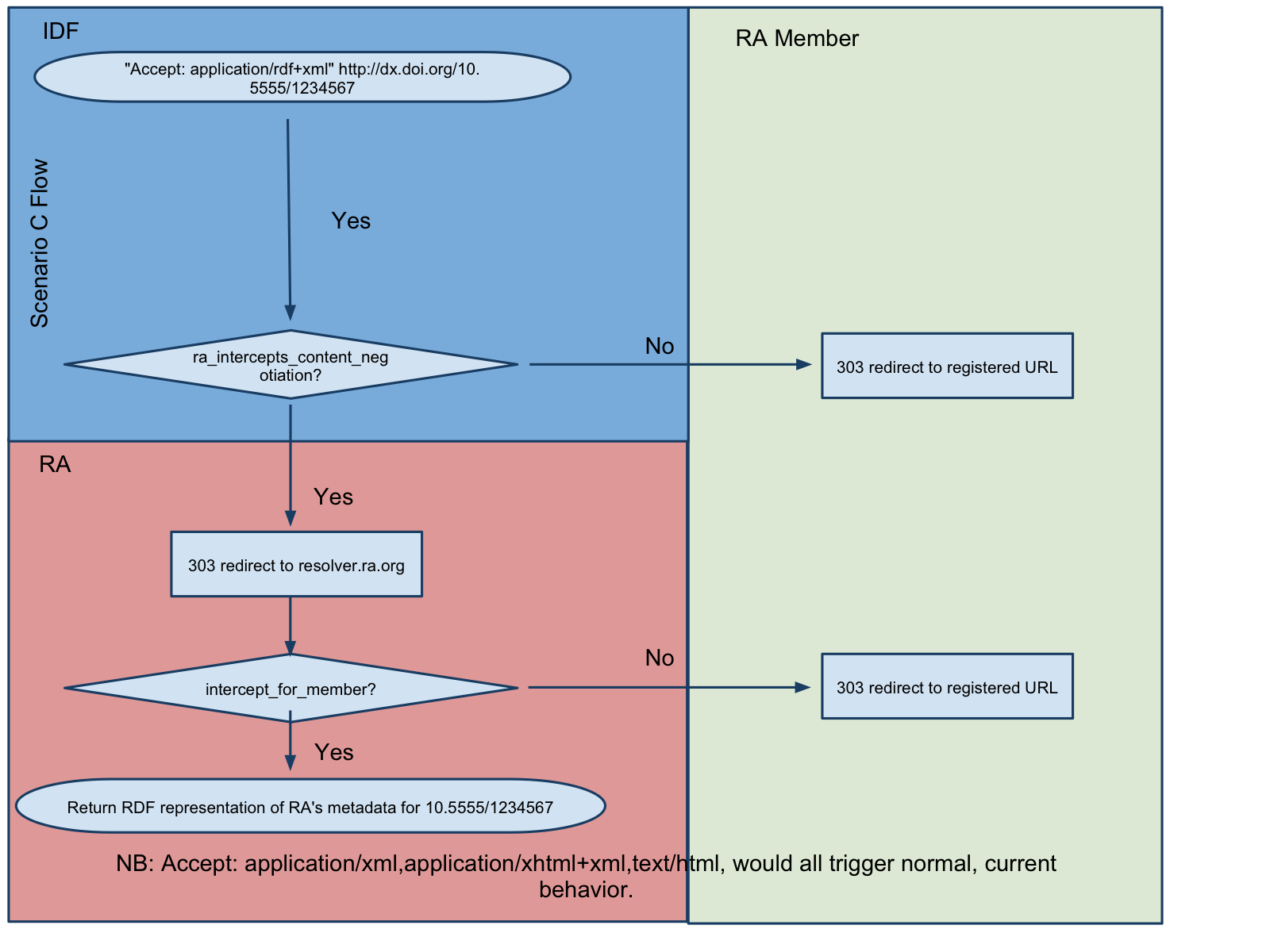
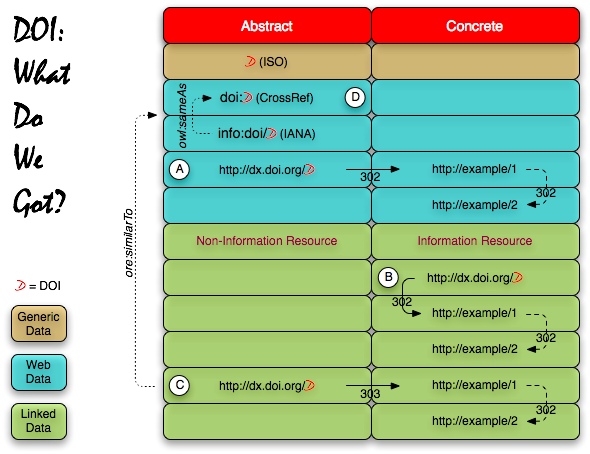
Since last month’s threads (here, here, here and here) talking about the issues involved in making the DOI a first-class identifier for linked data applications, I’ve had the chance to actually sit down with some of the thread’s participants (Tony Hammond, Leigh Dodds, Norman Paskin) and we’ve been able sketch-out