CrossrefFeesSustainabilityInformatique et sciences de l'informationAnglais
Publié
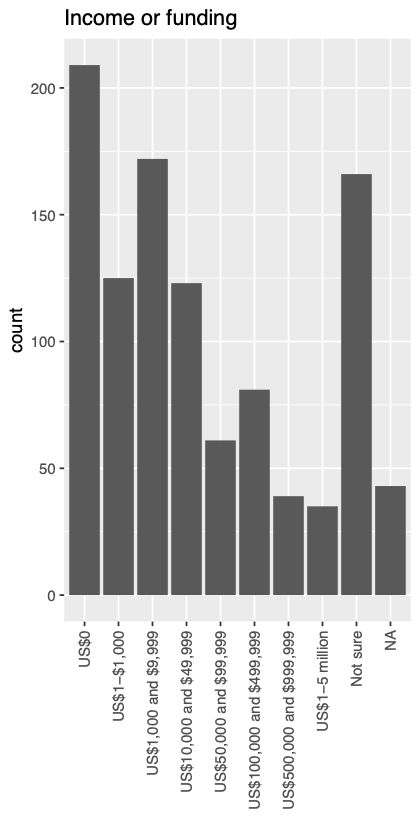
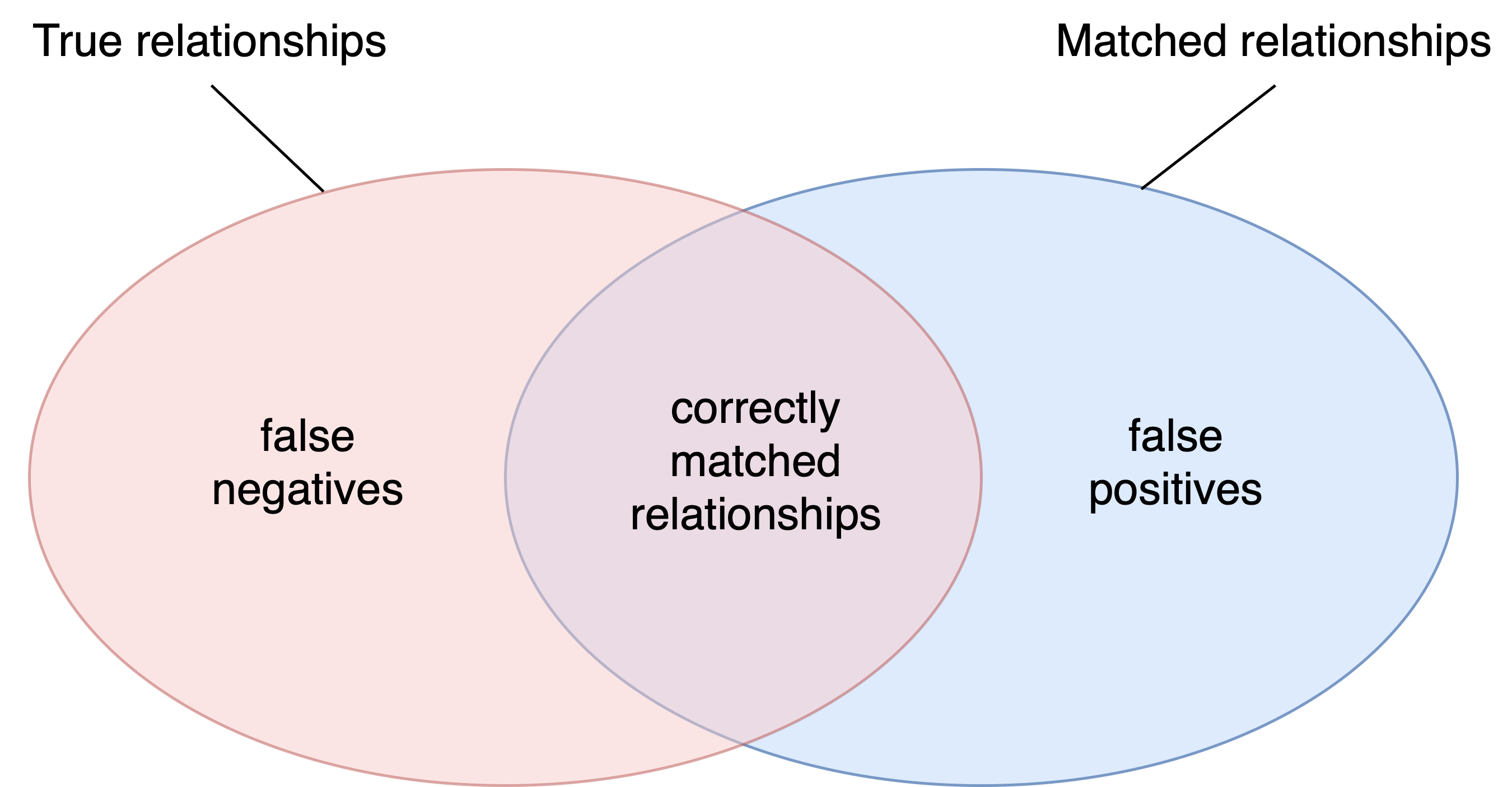
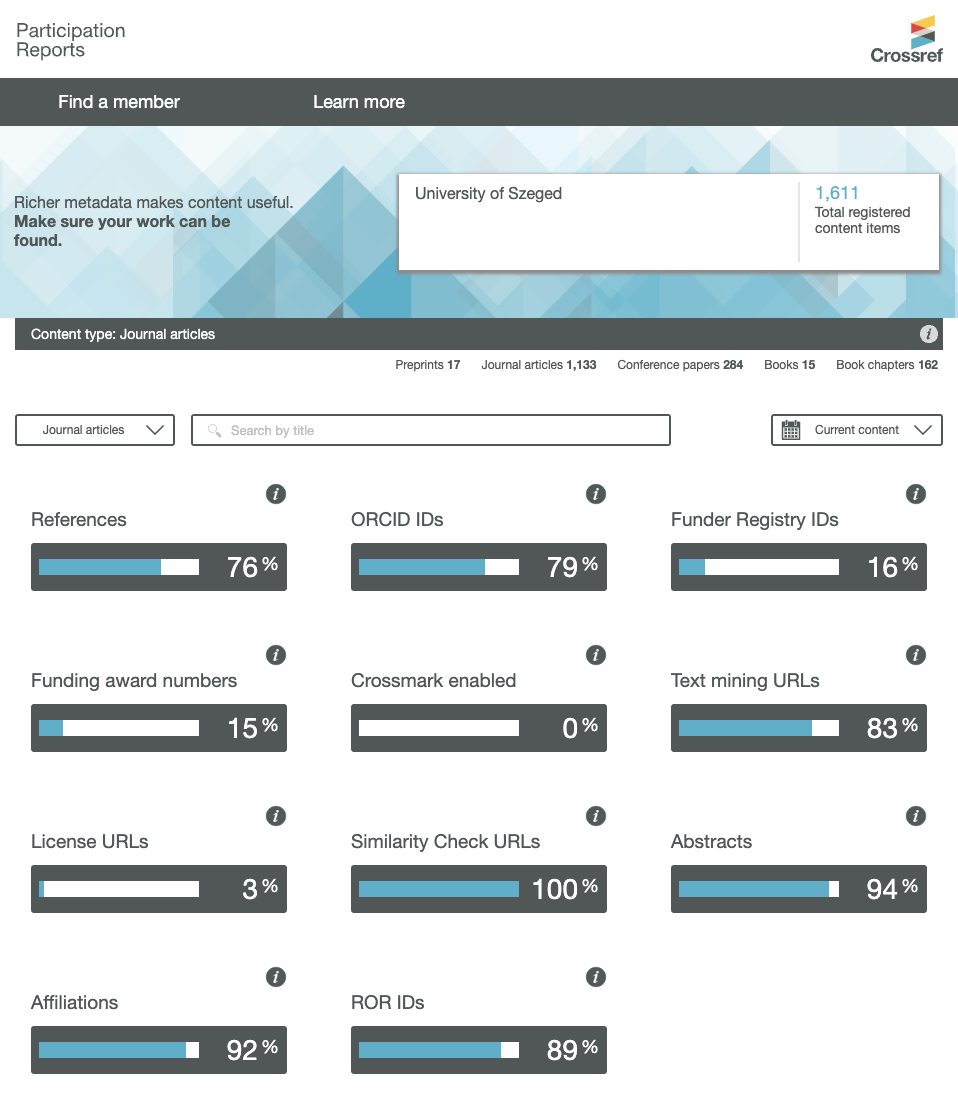
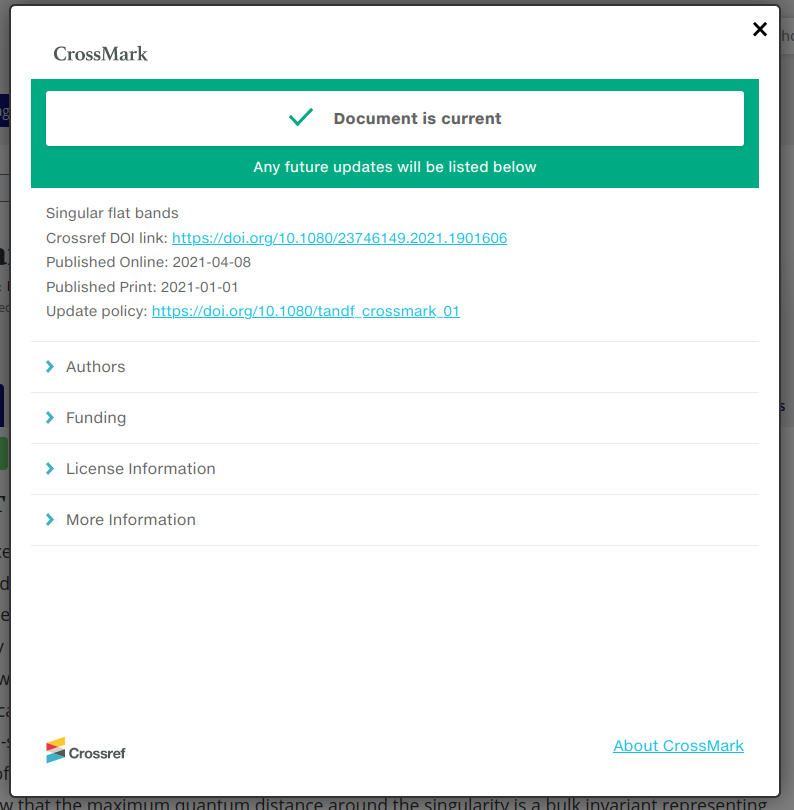
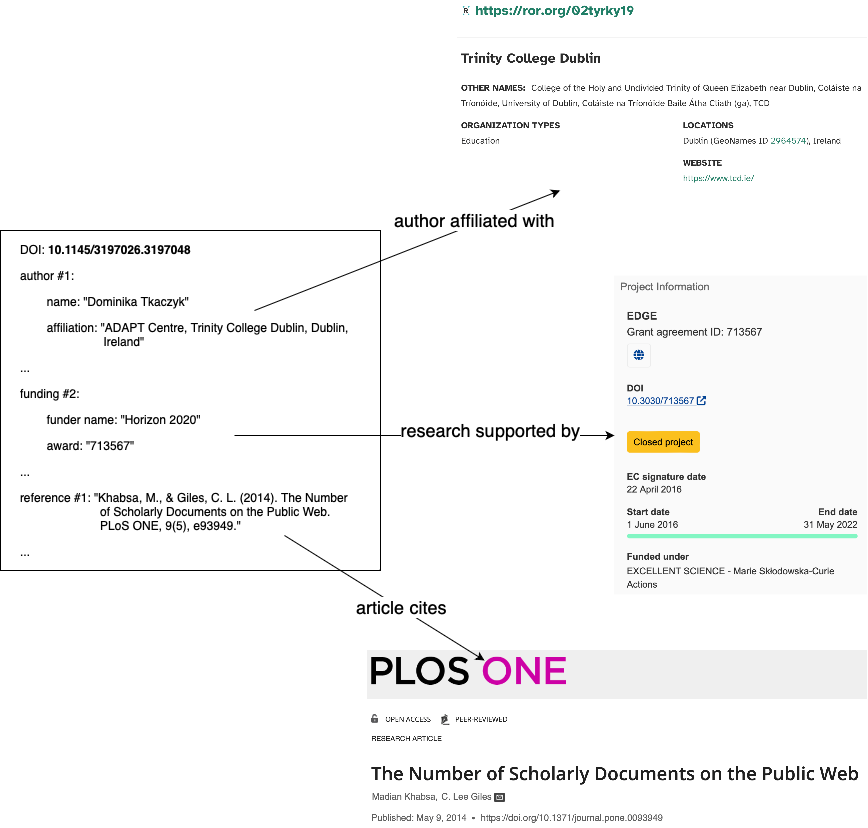
We’re in year two of the Resourcing Crossref for Future Sustainability (RCFS) research. This report provides an update on progress to date, specifically on research we’ve conducted to better understand the impact of our fees and possible changes.