Sciences de la terre et de l'environnementAnglais
Publié
Auteur Ted Habermann

Cite this blog as Habermann, T. (2022). Metadata Life Cycle: Mountain or Superhighway? Front Matter.
Cite this blog as Habermann, T. (2022). Metadata Life Cycle: Mountain or Superhighway? Front Matter.

Research activities depend on monetary and other support from a wide variety of state and federal agencies, universities, foundations, and individuals.

::::: {#block-4ce0cb5334f301eba820 .sqs-block .html-block .sqs-block-html block-type=“2” border-radii=“{"topLeft":{"unit":"px","value":0.0},"topRight":{"unit":"px","value":0.0},"bottomLeft":{"unit":"px","value":0.0},"bottomRight":{"unit":"px","value":0.0}}”} Connecting research is a critical element of the DataCite vision and two kinds of connections are supported by DataCite metadata.

One of the exciting new capabilities in Version 4.4 of the DataCite Metadata Schema is the capability to create unique identifiers (DOIs) for Output Management Plans, i.e., resourceTypeGeneral = OutputManagementPlan. This new resource type recognizes that research outputs can include many kinds of resources beyond just data: journal articles, software, computational notebooks, presentations, etc.

Metadata Game Changers, the Center for Expanded Data Annotation and Retrieval (CEDAR) at Stanford University, and Dryad are thrilled to announce their joint National Science Foundation two-year EAGER award focused on increasing the quality of disciplinary metadata and bridging the gap between generalist and disciplinary data repositories.

I have been working on finding RORs from affiliation strings again and have been struck by the number of people that provide acronyms as affiliation strings. We all know the rule for using acronyms in scientific writing is “write out the first occurrence completely” so the reader knows what the acronym stands for and most of us try to follow this rule.

The fundamental hypothesis being explored in this series of blogs is that identifiers of any kind, even if they occur just once, can be useful in domain repository metadata because individuals and organizations make multiple contributions to the repository and the corpus of scientific literature based on it. The goal of the work is to increase the number of identifiers in DataCite metadata associated with datasets created or archived at UNAVCO.

In previous blogs we used DataCite metadata for UNAVCO to demonstrate how identifiers could be found and spread through the metadata collection to improve connectivity for people and organizations. The community built around UNAVCO over time was a critical part of this process as community members, both individuals and organizations, make many contributions over time.

With Chris Beltz, S. Jeanette Clark, Peter Slaughter and Matt Jones from the Arctic Data Center ( https://ror.org/055hrh286 ) and NCEAS ( https://ror.org/0146z4r19 ). I have written several blogs about measuring metadata with goals of identifying good examples and quantifying improvements in metadata over time.
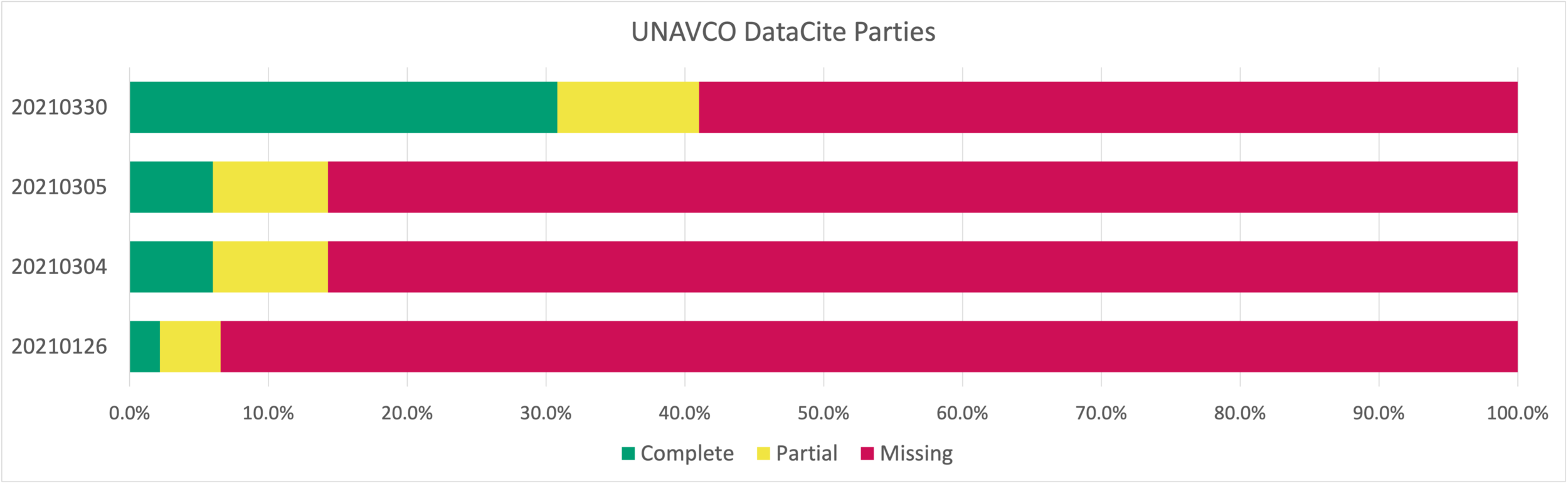
Most current metadata standards recognize that people and organizations play similar roles in the creation and management of datasets and other research objects. This dichotomy has been managed with the introduction of the concept of ‘party’ which, for example, could be a person, organization, or position in the ISO TC211 metadata standards for geographic data.

The UNAVCO DataCite Repository has over 5000 records that describe datasets created by researchers from many organizations, all of which are members of the tight-knit and well-established UNAVCO community. In the first blog of this series, I proposed that connecting these organizations to the PID Graph depends on having unique identifiers, i.e., RORs, for these organizations.